
CyberFraud Fusion: Decisioning on Requests 101
My background is from the fraud side, analysing events of data, usually results from an API. The world of IT, security and indeed many of the workings of the web were unfamiliar to me; a web developer tools window was like trying to read hieroglyphs.
I write this blog as an introduction to requests, and why decisioning there is great!
The tl; dr
Requests are the basis of internet communication. Moving decisioning to the request layer (cyber) with a fraud mindset is great because of the:
Cyber benefits
- supply the first point of interaction with known business logic = better, earlier detection and prevention of attacks
- remember previous requests for long time = dormant attackers remain blocked
Fraud benefits:
- track successful and failed request = proactive knowledge of how defences are being tested and probed for weaknesses
- plugin to where all interactions happen = no lengthy integration projects. and new pages available to monitor by default.
- don’t need to configure application layer stuff = no developer effort needed on that maintenance
Requesting clarification…
The internet fundamentally works on requests. They allow devices and servers to talk to each other and transfer the information needed to work. When you’re on a website, lots of these requests are going on to give you that browsing experience.

- Method: What are you trying to do? GET some information? POST some information somewhere? The method is what action you want your request to do. There is a set list of these, two of the most common being:
- GET: Retrieve data. eg. loading a website page is GETting the contents of that page.
- POST: Submit data. eg. entering your email+password and hitting login will POST those to the website.
- Scheme: How the request will be communicated. Examples are HTTP or HTTPS*; you may know these represented as a broken or secured padlock.
* the S stands for ‘secure’, which is perhaps somewhat leading. It just means the data is encrypted when sent vs. in the clear which could be easily snooped in transit. That does not guarantee the recipient can be trusted. - Host: You are sending a request out to the world. But who is it for? The host is like an address for who you want to answer. A resolving system called Domain Name System takes your host and figures out where to send your request (resolves it to an actual IP address, the fundamental identifier of the internet, ‘who’ you want to let know about your request).
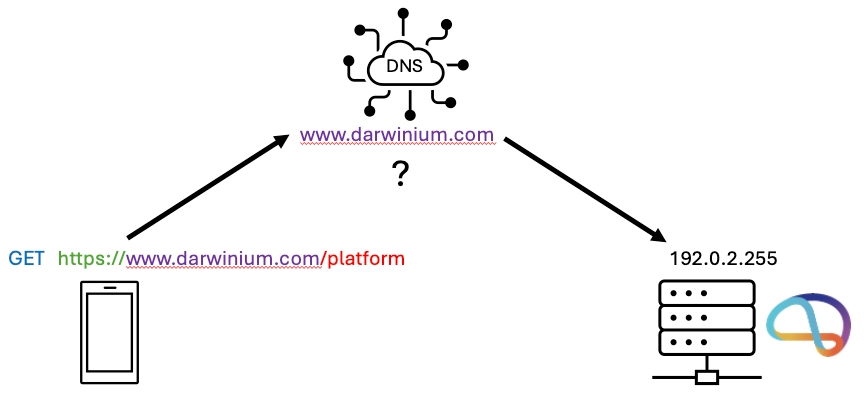
- Target (path, route): A receiving host can likely do lots of things. Example: deliver different pages on a website, like /login /home /pay etc. The target specifies which of those services you are specifically requesting.
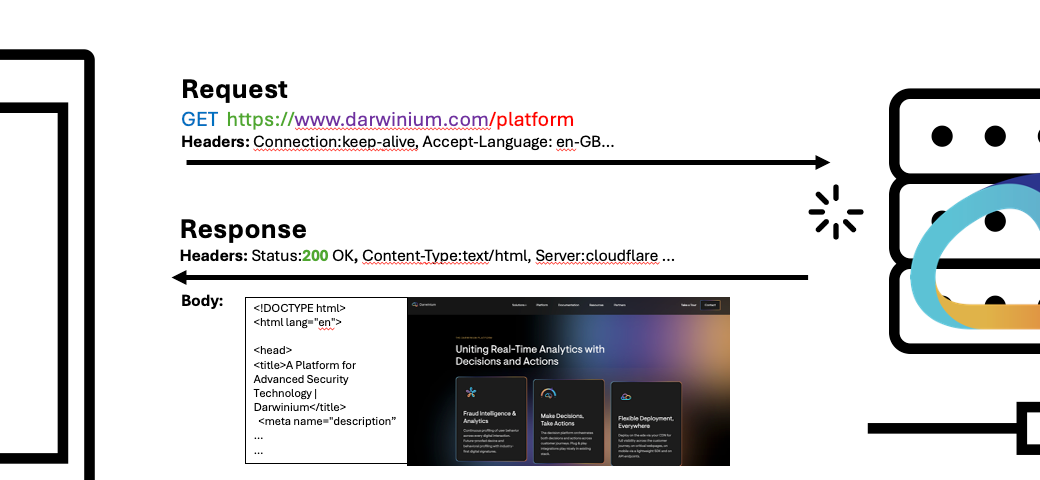
- Headers: Imagine getting a letter and it was just the body of the letter. You’d have a lot of questions right? (and maybe even a little freaked out). What is this about? Who is this from? When did they send it? Headers work in a similar way to the headers of a physical letter; they let you know summary things about the request like:
- Expected length of content
- The type of content in the request (formatting like JSON, text, HTML… )
- Authorization credentials if the request demands it
- User agent, which is declaring basic details of the device or application making the request
Additional parts of a request may be present, depending on method:
- Body: The body is the data you want to POST or the data you GET back; think of it like the actual writing in a letter. The format of expected of that data (a form, a block of JSON etc. ) is specified on a header.
- Parameters: On a GET request, there may be a need to specify some extra things. Those form parameters within the request itself, and are split by ampersands (&) after a question mark ? . For example, a search query for darwinium (q), and possibly a page number (page) appear at end:
https://www.google.com/search?q=darwinium&page=1
What say you, in response?
The response is what is returned to you. Think of it like receiving a letter back. It has the same things in response (headers, body etc.), but several more which give you context on what the receiver thought of your request.
Response Status Code
There’s a reason why they are called requests. Sure anyone, anywhere with or without permission can make a request. But there’s no obligation to perform your request. The response code is a 3 digit number letting you know a category of outcomes of your request.
| Status Code | Description | Examples |
| 2xx | Success. This is likely what we want to see :) | 200 - OK , the most common, indicates request was ‘all good’ |
| 3xx | Redirected. The place you requested doesn’t know, but he ‘knows a guy’ that might. | 301 - Moved permanently, the URL has changed to something else 302 - Found/temporarily moved, a new URL was redirected to, but all good to request here still |
| 4xx | Client Error. Your request could not be fulfilled. ‘Client’ means you… so they think you’ve done something wrong! | 401 - Unauthorized. The right permissions were not provided. For example, entering wrong login credentials. 404 - Not Found, you probably know this one already. The place you want may have existed at some point but its been deleted or migrated since, without the devs bothering to let you know… 418 - I’m a teapot* |
| 5xx | ‘Server Error’. Server here means them.. so the place you sent the request likely messed up somehow. | 502 - Service unavailable. You may have seen this. The server you’re trying to request from is down or overloaded. (spare a thought to those trying to get it back online for you) 503 - Bad gateway. You’ve probably seen this too. |
* This is a joke (but entirely valid) response code. Although given we now have the internet of things, where kitchen appliances are hooked up to the internet its maybe actually got a genuine purpose now.
Response Headers & Body
The response of a request likewise has headers and body to let you know how to handle the response and retrieve the data back. It’s the ‘application layer’ that takes requests and figures how to properly respond.
For example:
- The headers of responses that get a 3xx redirect code likely contain a ‘location’ header which lets you know the URL that was redirected to.
- The response body of a GET request to a website will contain the HTML of the page that ends up rendered in your browser
- Response body of requests that return a 4xx code may contain more context for refusing the request

Darwinium: Adaptation at the request layer
So, we’ve established we’re looking at requests, one step higher up in the chain. Where does the ‘fraud’ in CyberFraud fusion come in? And how does Darwinium benefit and take advantage of being deployed in the request layer?
Seeing is revealing
Think of the request layer as a border control checkpoint. You get to see everyone requesting entry to your estate, not just those that get through (which is the usual API approach to fraud, facilitated in the application layer).
As a fraud team, you get visibility of all BAD attempts, including:
- Invalid credentials
- Invalid token / cookie / proof of work, rejected by WAF etc.
- Requests to paths that don’t exist or aren’t referenced anywhere publicly
Those are an absolute goldmine for proactive visibility on how the journeys are being probed and attempted to be exploited, before they breach the defences
Benefits summary:
- Seeing requests = Proactive visibility into how architecture is being probed and the attempted exploits.
- New pages are visible and coverable immediately = no need for another implementation project
Dynamic Extract and Insert
Sitting within the request layer allows pre-approved manipulation of the request or response body and headers. Those manipulation instructions then scale incredibly well to any point they are needed across a journey.
Insertion is useful for inserting the additional Darwinium profiling scripts into the body of returned website pages.

Insertion is also useful for adding Headers to requests with extra insights and decisioning from Darwinium. That can be combined with extraction of any useful data and identifiers contained within the request too, to be considered and stored.
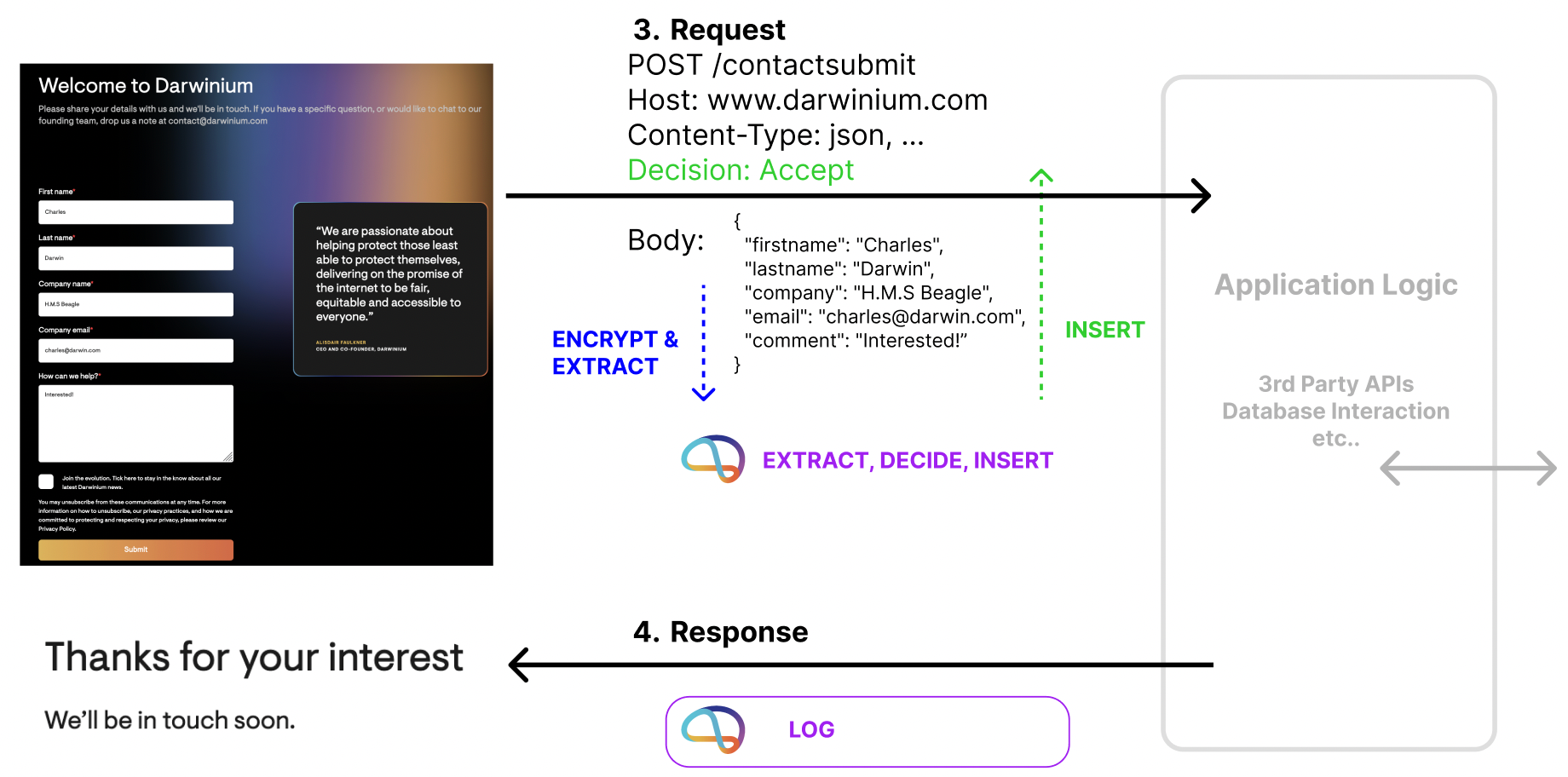
Darwinium performs both of those operations in a way that is configurable to application developers. In particular, the profiling script is clear-box and can be verified for authenticity. And request data extraction is both explicitly opt-in and encrypted before Darwinium sees it, preserving the privacy of that data. Those operations are easily replicated and repeated to across and many journeys.
Benefits summary:
- Fingerprinting inserted dynamically and flexibly anywhere = No need for engineering cycles for manual placement and upkeep
- Decision results can be inserted into request header = negate developer time and maintenance needed to orchestrate API calls everywhere, especially when just wanting to log that an interaction happened.
- Data in request can be extracted and encrypted dynamically = privacy preserving.
Remember remember, requests from (last) November
In most typical decisioning systems that observe requests, the requests very much come and go. The classic decisioning system is the Web Application Firewall. This is often demanded protection to fulfil compliance obligations and prevent clear compromise and attacks.
The problem is those platforms may offer week, day, or even as little as 15minutes of partial ‘lookback’. That’s usually enough to do what security are typically tasked with such as preventing DoS ( denial of service, too many requests in a short space of time that a server can’t process). But you typically want business and fraud prevention logic to stick around far longer.
Darwinium can takes the requests, extracts meaningful identifiers, augments with additional data and logs in both a real-time and analytics database able to remember and pivot statistics on those for the long term (1+ years).
Benefits summary:
- Remember requests for over a year = Longer term memory for lasting assurance and protection
- Apply statistical aggregates against those requests = detect longer term anomalies, have readily available lookback data for real-time models.
- Bring intelligence found by the business back to the first interaction layer = earlier, better prevention and detection.
Summary
This blog covered the basics of requests, responses and benefits of decisioning within the request layer.
For more details and to find out more about Darwinium: contact@darwinium.com
